
L’intelligence artificielle (IA) est désormais accessible à tous, même sans compétences avancées en programmation. Grâce à des outils comme Ollama, vous pouvez facilement télécharger, installer et exécuter des modèles d’IA directement sur votre PC. Dans ce guide, nous allons vous montrer comment procéder étape par étape.
Faire tourner des modèles IA sur son PC ou son Mac

Depuis ChatGPT, l’IA est partout. On l’utilise pour le travail, pour programmer ses vacances, pour relire ses mails. On lui pose des questions concernant l’univers et certains même l’utilisent comme un journal intime. On voit chaque semaine de nouveaux modèles ouverts au grand public comme très récemment avc GPT-OSS-20b et GPT-OSS-120b. Dans tout cela, comment est-ce qu’on fait pour avoir son propre modèle d’IA ? Est-il possible chez soi ou dans son entreprise d’avoir son IA dédiée à une tâche sans passer par un géant technologique comme Microsoft ou OpenAI ? La réponse est Oui ! D’ailleurs, c’est même possible de faire cela en utilisant des logiciels libres et open source.
Qu’est-ce qu’Ollama ?
Ollama est une application open-source qui permet d’exécuter des modèles d’IA localement sur votre machine. Elle est conçue pour être simple d’utilisation, légère et compatible avec une variété de modèles, comme Llama, Mistral, Gemma et bien d’autres.
Prérequis avant l’installation
Avant de commencer, assurez-vous que votre PC répond aux exigences suivantes :
- Système d’exploitation : Windows 10/11, macOS ou Linux.
- Espace disque : Au moins 8 Go d’espace libre pour les modèles et les dépendances.
- Mémoire vive (RAM) : 8 Go minimum (16 Go recommandés pour une meilleure performance).
- Processeur : Un CPU moderne (Intel i5/AMD Ryzen ou supérieur). Un GPU (NVIDIA ou AMD) est un plus pour accélérer les calculs.
Téléchargement et installation d’Ollama
Pour installer et utiliser Ollama il va falloir utiliser le Terminal. Ce n’est que quelques lignes de commandes relativement simplifiés, cependant l’application ne propose pas par défaut une interface graphique.
Sur Windows et macOS
- Télécharger Ollama : Rendez-vous sur le site officiel d’Ollama : ollama.ai. Cliquez sur le bouton de téléchargement correspondant à votre système d’exploitation.
- Installer Ollama :
- Ouvrez le fichier téléchargé (
.exepour Windows,.dmgpour macOS). - Suivez les instructions d’installation à l’écran.
- Sur Windows, cochez la case pour ajouter Ollama au PATH si cette option est proposée.
- Ouvrez le fichier téléchargé (
- Vérifier l’installation : Ouvrez un terminal (ou PowerShell sur Windows) et tapez la commande suivante :
ollama --versionSi la version d’Ollama s’affiche, l’installation est réussie.
Sur Linux
- Installer via la ligne de commande : Ouvrez un terminal et exécutez la commande suivante :
curl -fsSL https://ollama.ai/install.sh | shSuivez les instructions pour finaliser l’installation. - Vérifier l’installation : Tapez la commande :
ollama --version
Télécharger un modèle d’IA avec Ollama
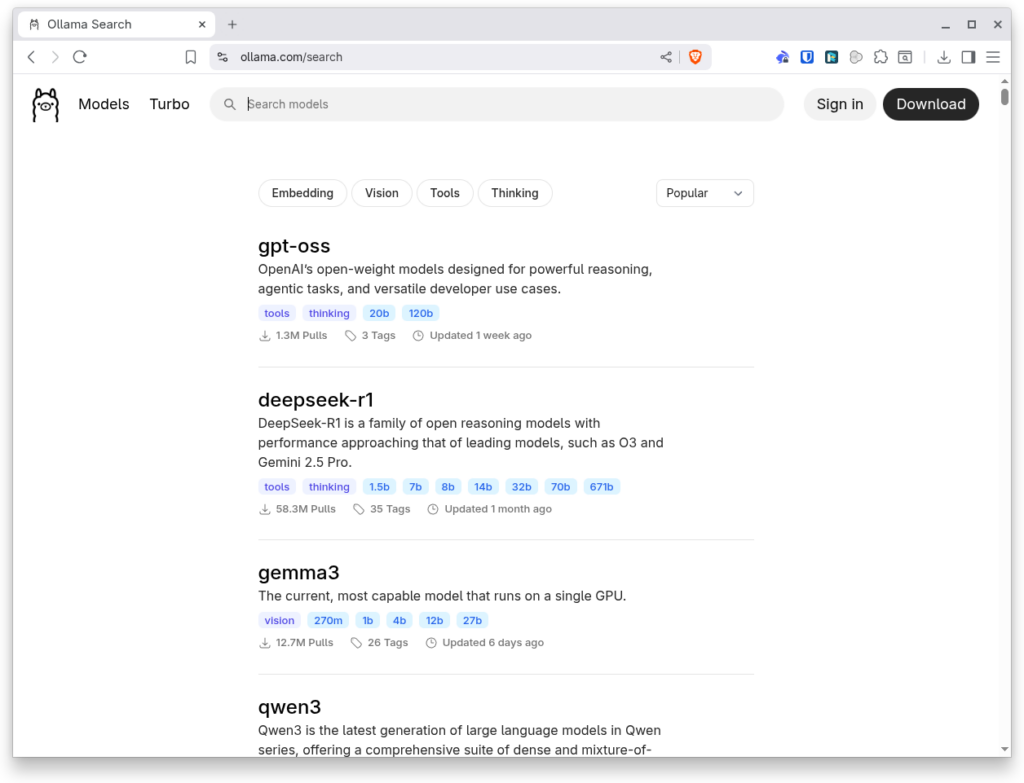
Une liste des modèles est disponible sur le site officiel. Vous pouvez télécharger Qwen d’Alibaba, GPT d’OpenAI, Gemma de Google. Bref, beaucoup des modèles open source du moment sont présents.
Ollama permet de télécharger facilement des modèles d’IA populaires. Voici comment procéder :
- Lister les modèles disponibles : Dans votre terminal, tapez :
ollama list(Cette commande affichera les modèles déjà téléchargés.) - Télécharger un modèle : Par exemple, pour télécharger le modèle Llama 3, utilisez :
ollama pull llama3 - Remplacez
llama3par le nom du modèle de votre choix (ex. :mistral,phi3, etc.). - Vérifier le téléchargement : Une fois le téléchargement terminé, tapez à nouveau :
ollama listLe modèle téléchargé devrait apparaître dans la liste.
5. Exécuter un modèle d’IA localement
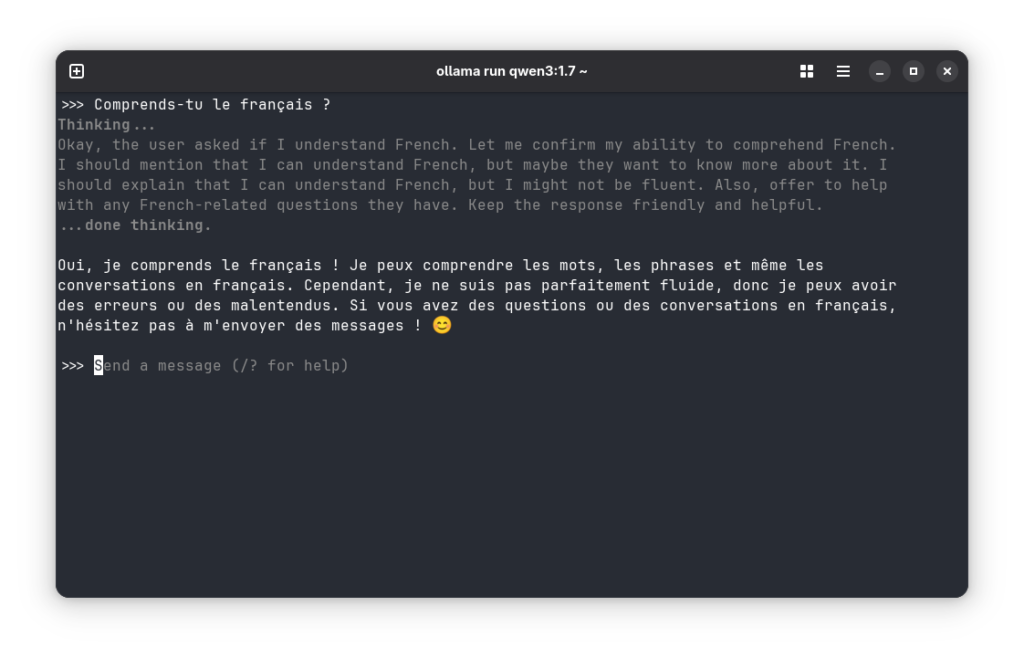
Maintenant que votre modèle est téléchargé, vous pouvez l’exécuter en local.
- Lancer le modèle : Utilisez la commande suivante pour démarrer une session avec le modèle :
ollama run llama3(Remplacezllama3par le nom de votre modèle.) - Interagir avec l’IA : Une fois le modèle lancé, vous pouvez lui poser des questions directement dans le terminal. Par exemple :
>>> Qu’est-ce que l’intelligence artificielle ?Le modèle répondra en temps réel. - Arrêter le modèle : Pour quitter la session, tapez
/byeou utilisez le raccourciCtrl + C.
Les limitations liées à l’utilisation d’un CPU ou d’un manque de RAM
Parce que tout n’est pas tout rose, vous le devinez sûrement, executer un LLM sur son PC n’est pas aussi facile que d’en utiliser en ligne. Exécuter des modèles d’IA localement avec Ollama peut rapidement rencontrer des limites matérielles, surtout si votre machine ne dispose que d’un CPU standard ou d’une mémoire vive (RAM) insuffisante. Les modèles d’IA modernes, comme Llama 3 ou Mistral, sont conçus pour fonctionner de manière optimale avec des GPU dédiés (comme ceux de NVIDIA ou AMD), capables d’accélérer les calculs parallèles nécessaires au traitement du langage naturel. Sans GPU, un CPU seul peut ralentir considérablement les temps de réponse, rendant l’expérience moins fluide, voire frustrante pour des tâches complexes ou des requêtes longues. Pensez aussi bien refroidir votre machine.
De plus, un manque de RAM (moins de 8 Go, par exemple) peut entraîner des erreurs de mémoire, des plantages, ou forcer le système à utiliser la mémoire virtuelle (le disque dur), ce qui dégrade encore les performances. Certains modèles légers, comme Phi-3 ou TinyLlama, sont mieux adaptés aux configurations modestes, mais les modèles plus puissants nécessitent souvent 16 Go de RAM ou plus pour fonctionner correctement. Si votre PC est limité en ressources, privilégiez des modèles optimisés pour les environnements légers, ou envisagez une mise à niveau matérielle pour profiter pleinement des capacités de l’IA locale. Enfin, gardez à l’esprit que les tâches gourmandes en calcul (comme la génération de texte long ou le fine-tuning) peuvent être difficiles, voire impossibles, sans une configuration adaptée.
Conclusion
Avec Ollama, exécuter un modèle d’IA sur votre PC n’a jamais été aussi simple. Que vous soyez développeur, chercheur ou simplement curieux, cet outil vous permet d’explorer les possibilités de l’IA en local, sans dépendre de services cloud.
N’hésitez pas à expérimenter avec différents modèles et à partager vos retours avec la communauté Ollama !